
Serverless, as related to compute, has been extensively covered. We know that impacting the developer experience of creating functions and managing the lifecycle can make or break an approach. The tooling experience for serverless is getting better but still not perfect. Still, I feel we understand well and recognize that work is required to create a seamless experience for the developer creating, deploying, testing, and maintaining functions.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
Serverless data is an entirely different kettle of fish. As the industry moves towards DevOps, full-stack, and Serverless, there is a responsibility for the application team to do everything. One area that I think many engineers struggle with is data. In the olden days, the DBA was a magician – they could perform wondrous things to speed things up and “make good.” Every data service will now start to claim serverless (as it’s the term in vogue). Let’s explore the seven tenets of serverless data and hopefully provide some guidance about data in a serverless architecture.
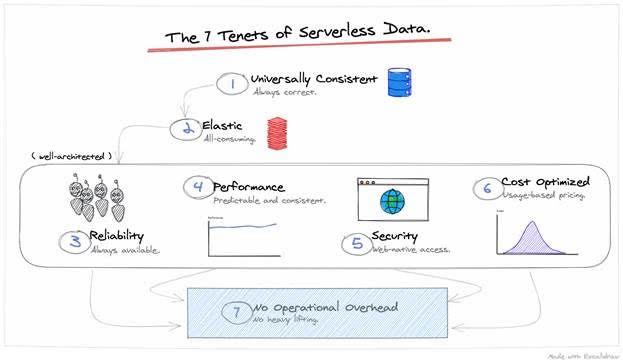
No operational overhead – No heavy lifting
The most significant feature of serverless data is low operational overhead. The process of tuning a database for production usage and ensuring we have the headroom to handle a burst in access is not trivial. A serverless approach should take the load we throw at it automatically. The system is offered as a service – no installations or upgrades. Any operational work is eliminated, and we preserve operational transparency. A key enabler is ‘Configuration as Code’ – let’s reduce toil as much as possible (toil meaning the SRE definition of “work that is manual, repetitive and automatable”). Developers should be able to capture what configuration they need to do in code. The days of upgrading the database are also gone – serverless data must be low maintenance. It’s the Toyota of the database world – the thing must run forever.
Elastic – all-consuming
Serverless, and modern cloud systems, are all starting to have one thing in common – Event-Driven Architectures. With the scale that modern applications deal with and the number of microtransactions coming at systems, event-driven is becoming the norm. If the system is infinitely scalable, then that means two things. First, with a #NoOps mindset, you can not inform the system in advance that there is a traffic burst coming (even if you know), and second, you cannot afford to lose that traffic. A serverless data system will offer infinite capacity at any time, and there is no manual configuration or provisioning necessary to access that capacity. It is an API. The days of reactive systems that don’t handle traffic spikes are behind us. A serverless data solution must scale horizontally, so being “event-native” is a sensible expectation.

Reliability – Always available
As a service that has a zero operations model, then reliability is passed to the service provider. The requirement is simple – data must be highly available at all times. The first concern for engineers is that a data operation has succeeded; this is table stakes. Serverless, by default, is via an API call – the underlying system must also be highly available. Serverless is cloud-native, which means you are not installing instances in regions and managing them. There should be an ephemeral and elastic nature to the underlying system, a level of resiliency that we expect in the modern cloud. This also means that the system should remain available if there is an issue with a single region.
There is no single point of failure; your data is highly available at all times. In the new world of serverless data, all of this is wrapped up in a managed service – which means the vendor does all the work for you.
Performance – predictable and consistent
The first two fallacies of distributed computing are “the network is reliable” and “latency is zero.” We can’t promise those will both be true, but our goal is low latency from everywhere. This aims to give predictable performance. As a foundational requirement, it is then critical to avoid potential serverless traps. There are no cold start issues, and serverless data must be tuned to provide predictable performance.
Universally consistent – always correct
Extending the ACID (Atomicity, Consistency, Isolation, and Durability) concept further, we require that all data is transactionally correct (Consistent) and there are no locking issues between transactions (Isolation). As a consumer, it should not be any of your concern how this is achieved, just that it is, and you can rely on it. If there is work required outside of the service to compensate for consistency, the solution does not do its job.
Security – web-native access
Access to data must be simplified but robust. Serverless is cloud-native; therefore, the data system should be loosely coupled and driven by a declarative API. This may sound straightforward, but there are implications. A network architecture or VPC mustn’t constrain data access. Should serverless data use web-native access patterns over local network access patterns? Ubiquitous access would imply that web-native access is required. Database APIs must be exposed on the public internet, use standard security protocols and be safe – regardless of browser, mobile, or backend. There is no requirement to create custom security patterns using VPCs or gateways – this creates additional work and risk. Why shouldn’t data interoperate with the web ecosystem, like any other component? Why not indeed.
Cost-optimized – usage-based pricing
Often the headline that follows “serverless” is usage-based pricing. The six previous tenets are often overlooked or misunderstood by consumers. Sometimes it’s difficult to see beyond price. Usage-based pricing means precisely that – billing is based on API calls, on operations – not per container, not per virtual machine, and not per instance or minute of machine resources consumed. Of the serverless databases in the market, Fauna demonstrates serverless metered pricing very well. The free monthly capacity allows instant experimentation, with no credit card required. Additional plans are metered with a pay-per-use approach. Crucially, this means that the system is designed to be very efficient with compute and needs an elegant and performant architecture under the hood. When traffic bursts, you don’t mind paying for it as you are (hopefully) serving more customers. When traffic drops to zero, then cost drops dramatically. As part of serverless architecture, it’s possible to get to a FinOps mindset where you can plan and track your budgets and business meticulously.
As you can see, the seven tenets of serverless data are consistent with what we have been learning around serverless compute. Will this require some traditional database solutions to think differently? As is often the case, when a term starts to become popular, everyone will stick X after their product name. How many vendors rebranded their ProductX to be ProductX Cloud in recent years? Upon further investigation, many of these solutions are cloud-ready, not cloud-native. We will see the same with serverless data – many vendors will adopt a different pricing model and claim serverless.
Fauna, DynamoDB, CosmosDB and others are leading the charge on building on these serverless data tenets to deliver a platform that you can grow with. I encourage you to try one, as stated earlier, Fauna has a generous free tier, so try it for yourself and see if it meets these tenets, while meeting your database requirements. One thing is true when your application starts hitting some heavy load – the database is always a potential bottleneck. Using these tenets and selecting a good solution for you is a great way to practice problem prevention. Excellent engineering is about preventing problems from happening – use these tenets wisely.




